1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
|
import logging
import requests
import re
from urllib.parse import urljoin
import pymongo
import multiprocessing
mongo_client = pymongo.MongoClient("mongodb://10.210.100.131:27017/")
db = mongo_client['r1_movies']
collection = db['movies']
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s')
BASE_URL = "https://ssr1.scrape.center"
TOTAL_PAGE = 10
def scrape_index(page):
index_url = f'{BASE_URL}/page/{page}'
return scrape_page(index_url)
def scrape_page(url):
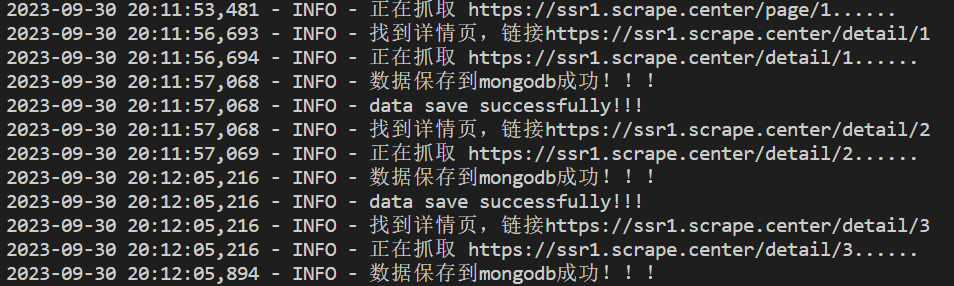
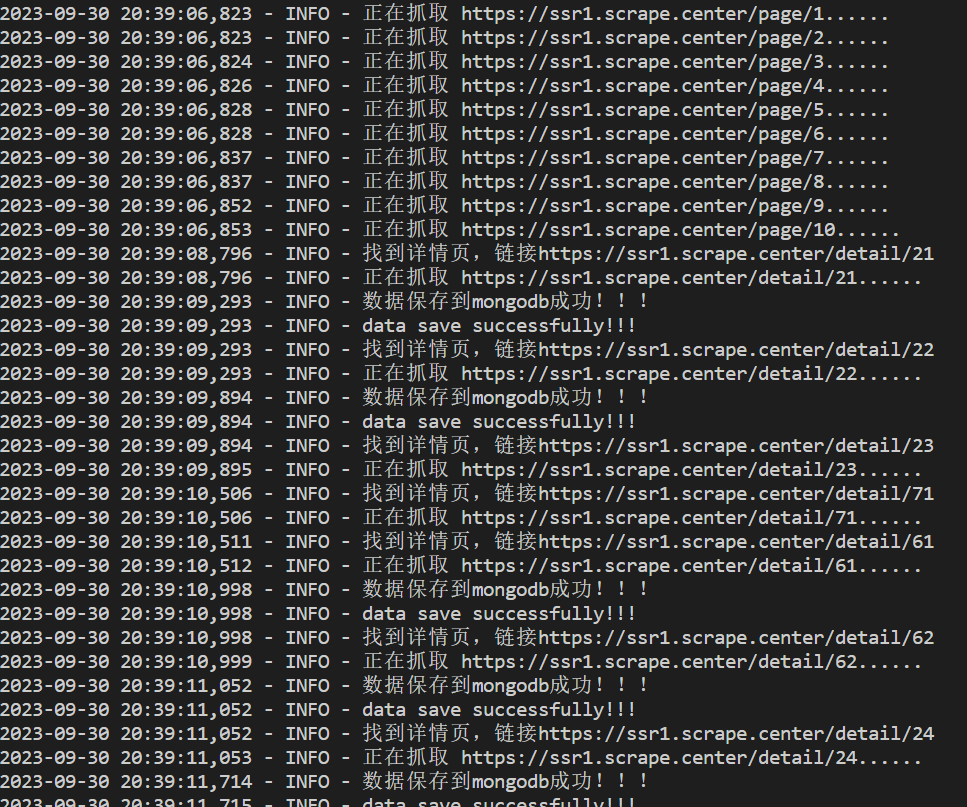
logging.info("正在抓取 %s......",url)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
logging.error("爬取%s时返回无效的状态码%s" % (url,response.status_code))
except requests.RequestException:
logging.error("爬取%s发生异常" % url,exc_info=True)
def parse_index(html):
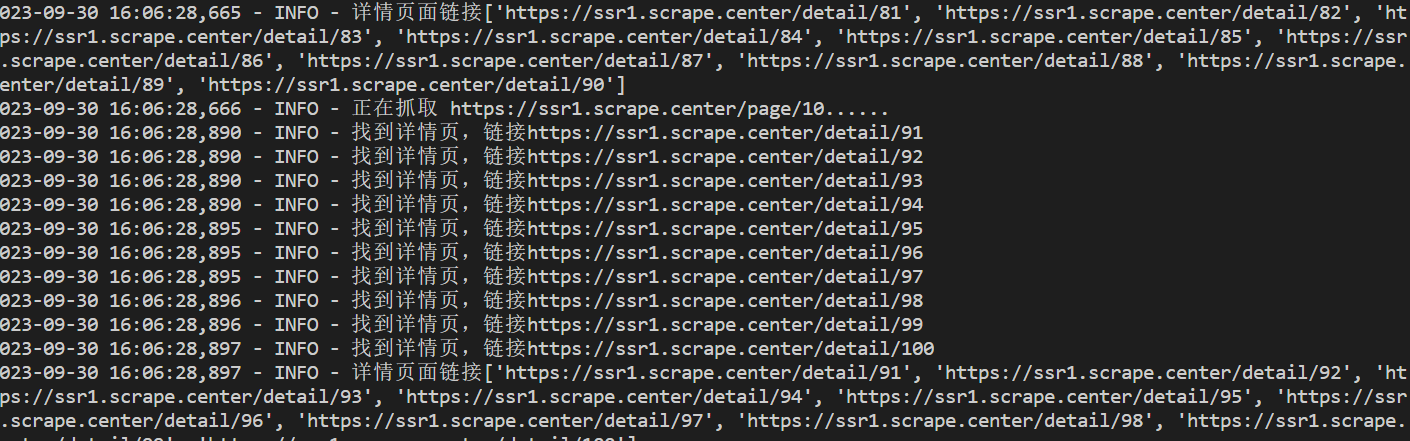
pattern = re.compile('<a.*href="(.*?)".*?class="name">')
items = re.findall(pattern,html)
if not items:
return []
for item in items:
detail_url = urljoin(BASE_URL,item)
logging.info("找到详情页,链接%s"%detail_url)
yield detail_url
def scrape_detail(url):
return parse_detail(scrape_page(url))
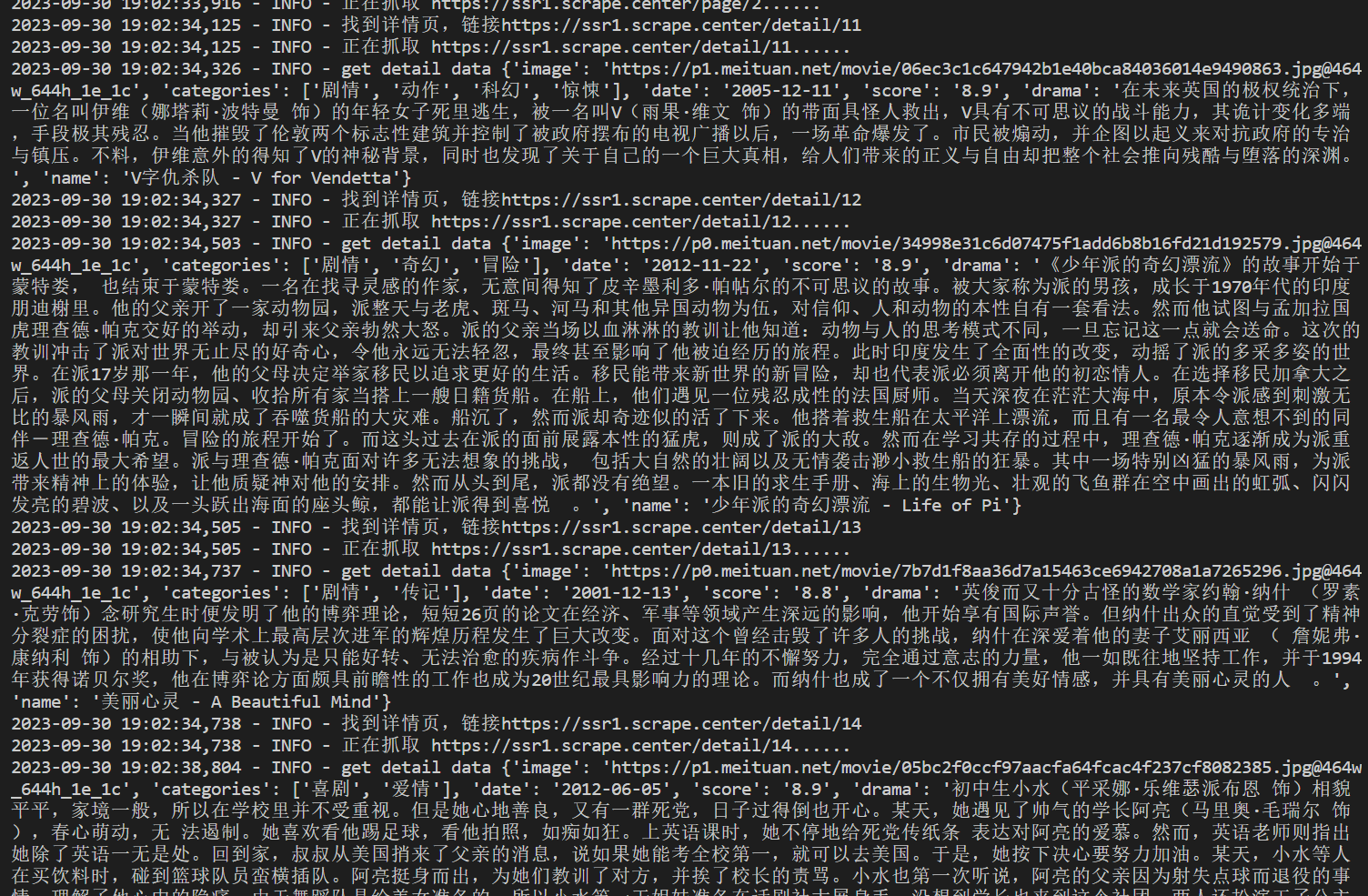
def parse_detail(html):
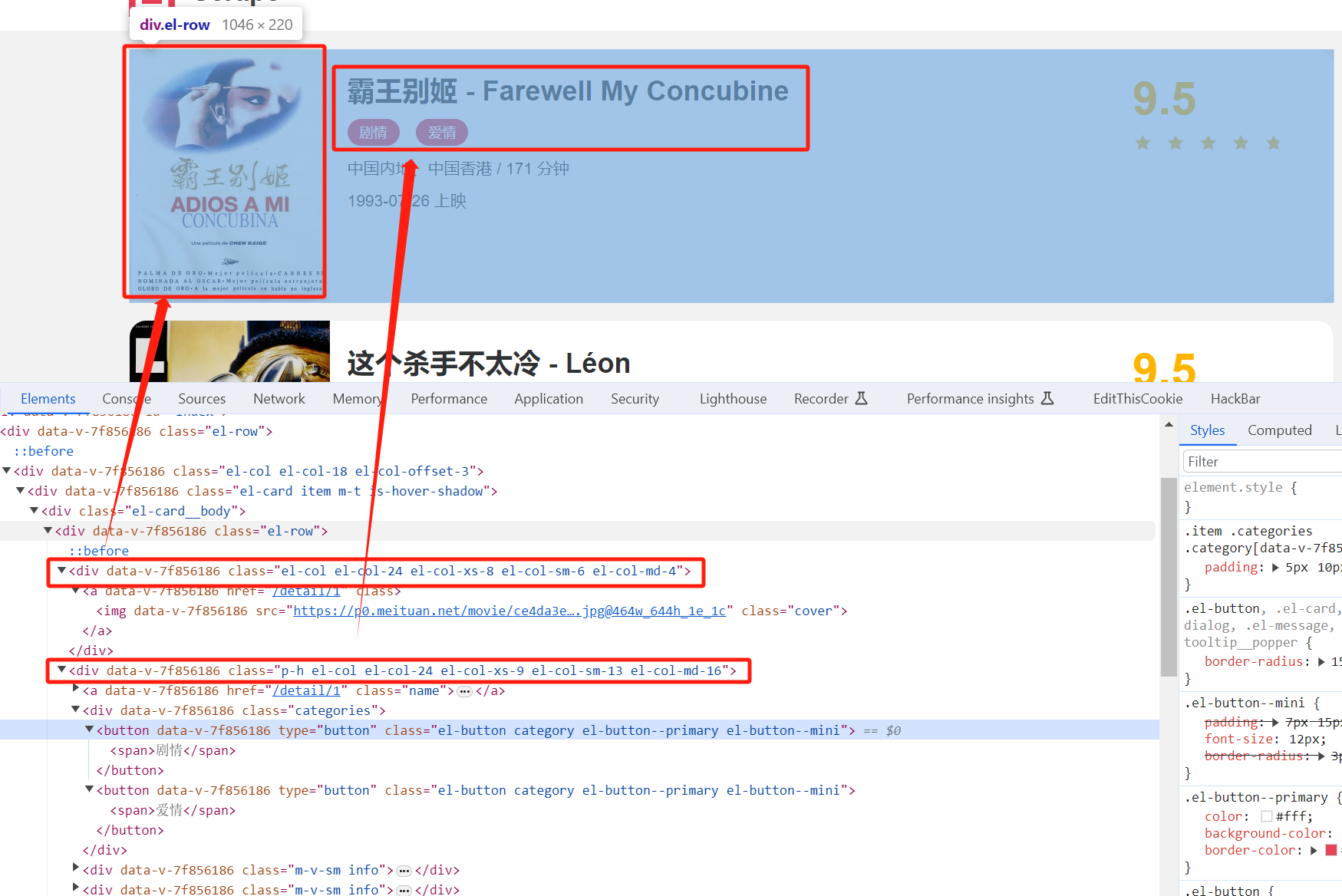
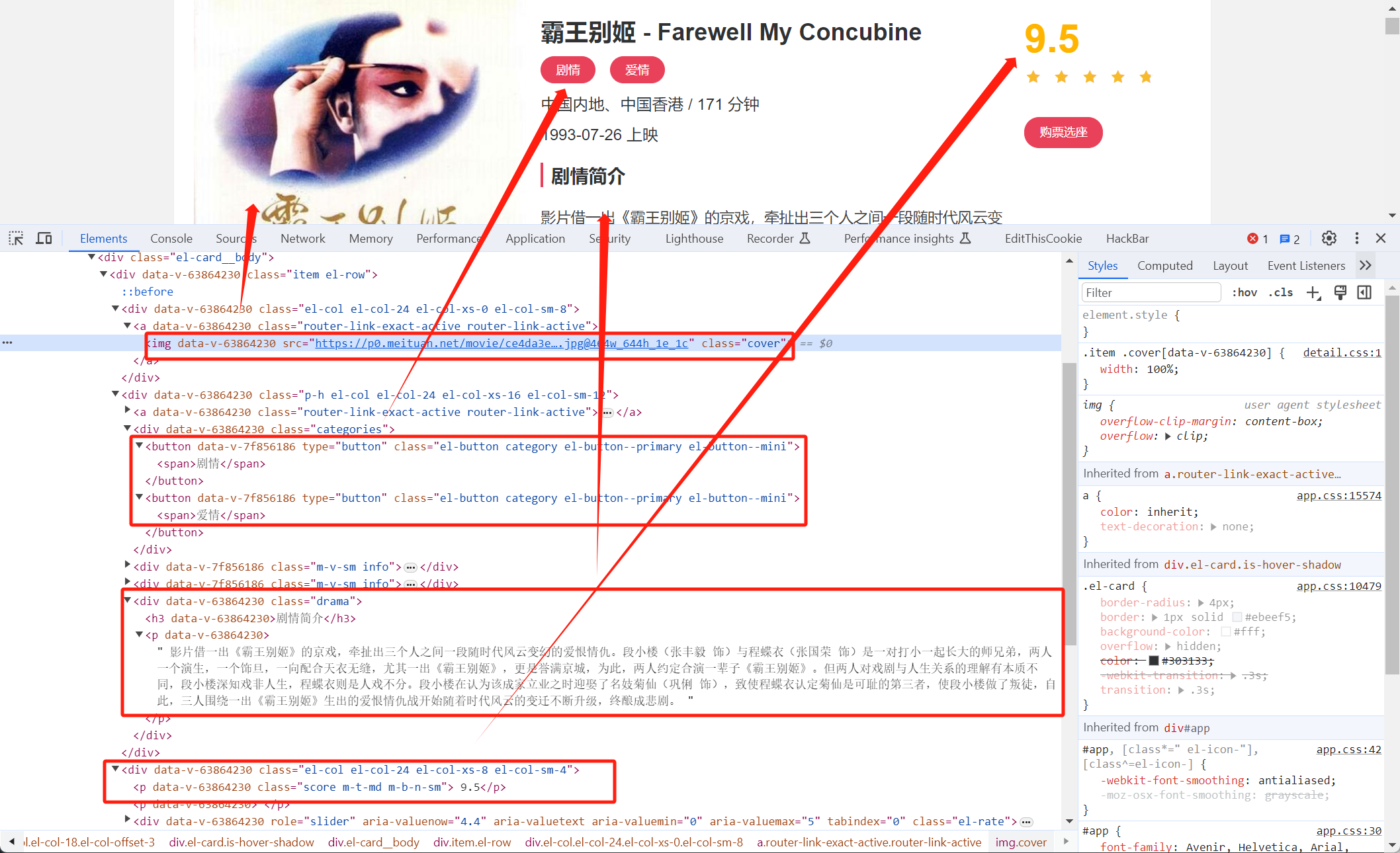
img_pattern = re.compile('class="el-col.*?<img.*?src="(.*?)".*?class="cover">',re.S)
img_url = re.search(img_pattern,html).group(1).strip() if re.search(img_pattern,html) else None
categories_pattern = re.compile('<button.*?category.*?<span>(.*?)</span>.*?</button>',re.S)
categories = re.findall(categories_pattern,html) if re.findall(categories_pattern,html) else None
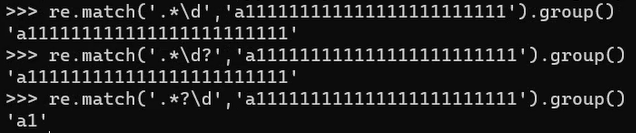
date_pattern = re.compile('(\d{4}-\d{2}-\d{2})\s?上映')
date = re.search(date_pattern,html).group(1) if re.search(date_pattern,html) else None
score_pattern = re.compile('<p.*?score.*?>(.*?)</p>',re.S)
score = re.search(score_pattern,html).group(1).split() if re.search(score_pattern,html) else None
drama_pattern = re.compile('<div.*?drama.*?>.*?<p.*?>(.*?)</p>',re.S)
drama = re.search(drama_pattern,html).group(1).strip() if re.search(drama_pattern,html) else None
name_pattern = re.compile('<h2.*?m-b-sm.*?>(.*?)</h2>',re.S)
name = re.search(name_pattern,html).group(1) if re.search(name_pattern,html) else None
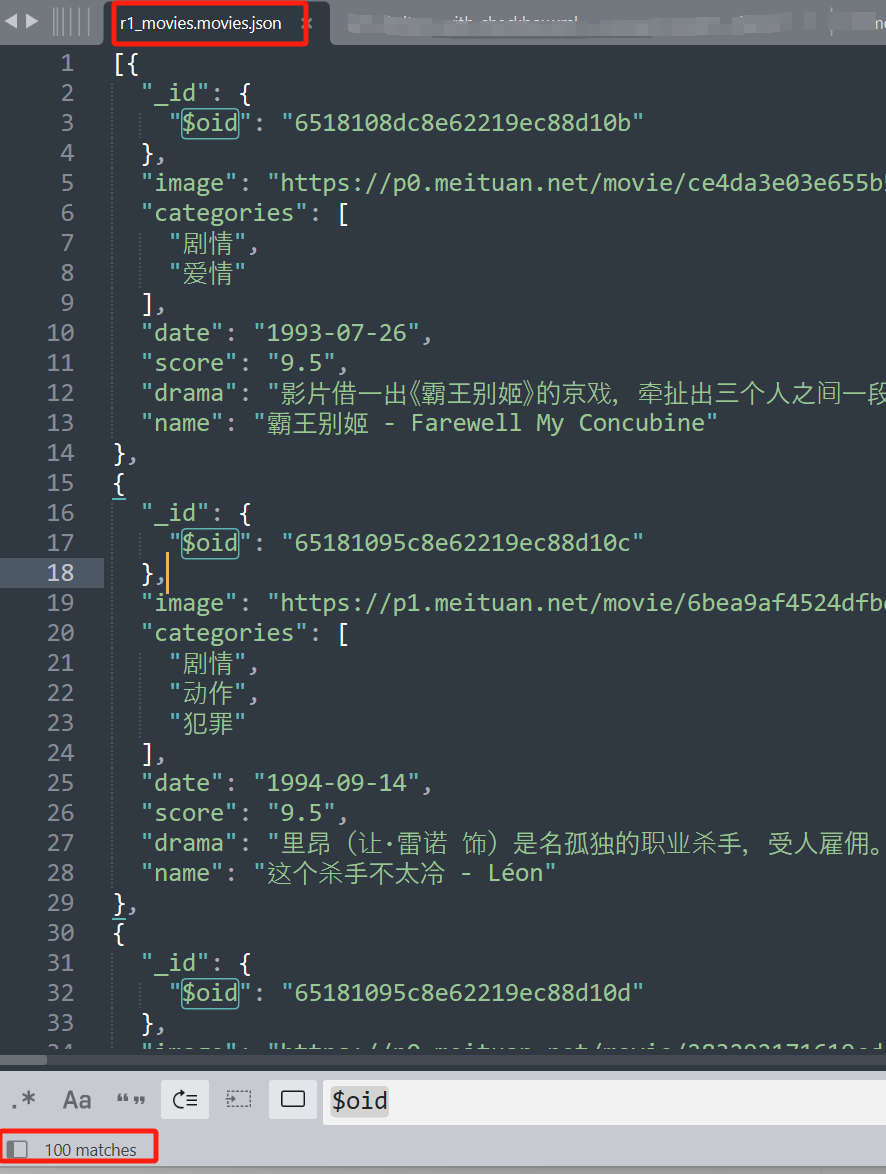
return {
'image':img_url,
'categories':categories,
'date':date,
'score':score[0],
'drama':drama,
'name':name
}
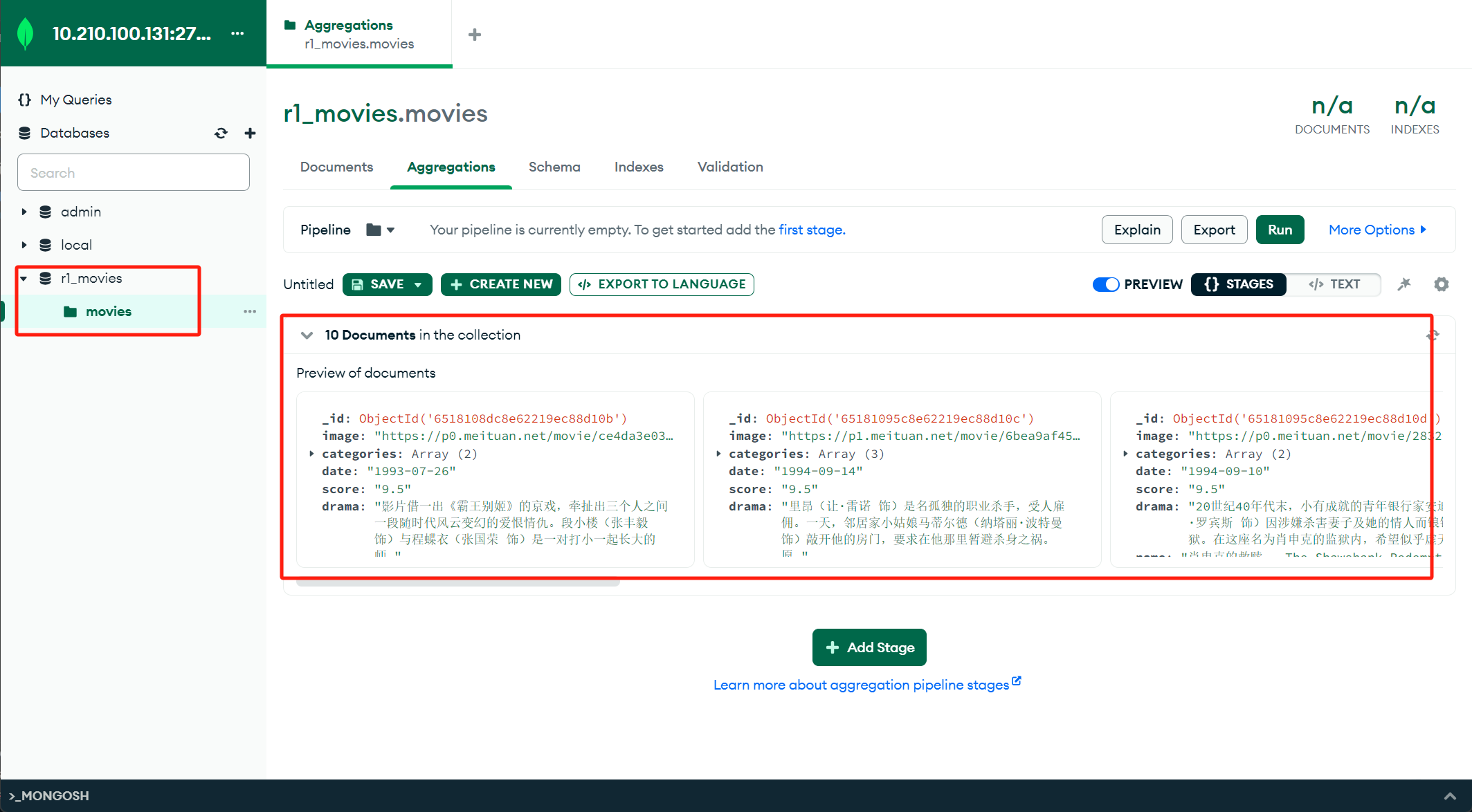
def save_data(data):
collection.insert_one(data)
logging.info("数据保存到mongodb成功!!!")
def main(page):
index_html = scrape_index(page)
detail_urls = parse_index(index_html)
for detail_url in detail_urls:
data = scrape_detail(detail_url)
save_data(data=data)
logging.info("data save successfully!!!")
def run_main(page):
main(page)
if __name__ == "__main__":
num_process = multiprocessing.cpu_count()
pool = multiprocessing.Pool(num_process)
page_to_scrape = list(range(1,TOTAL_PAGE+1))
pool.map(run_main,page_to_scrape)
pool.close()
|