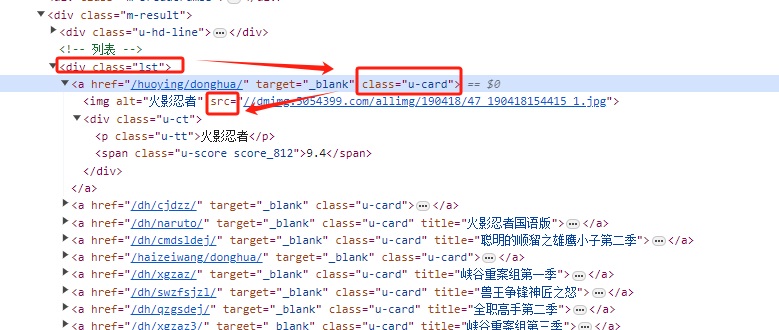
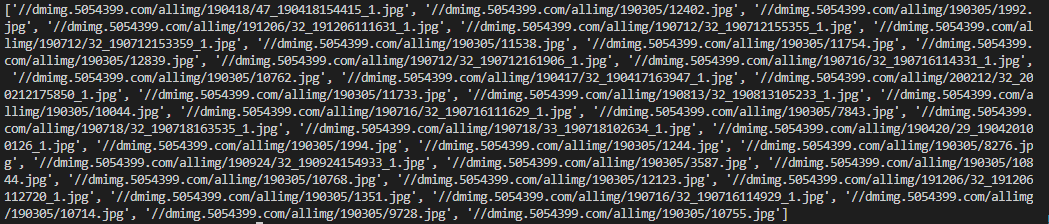
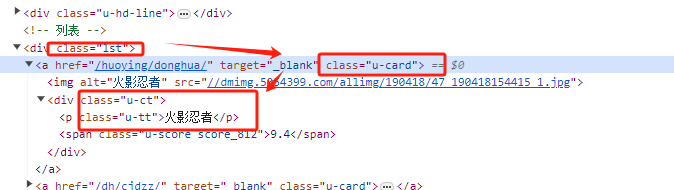
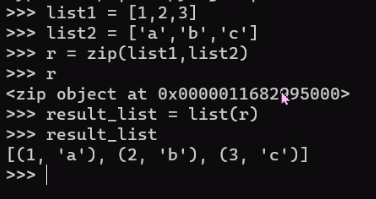
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
|
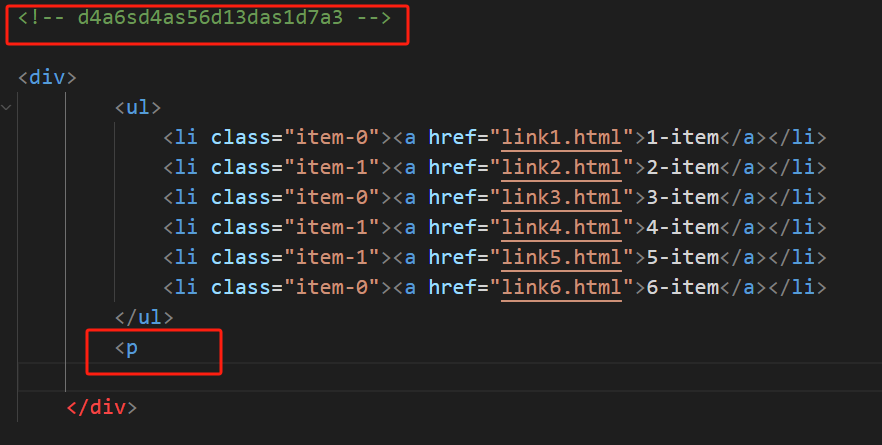
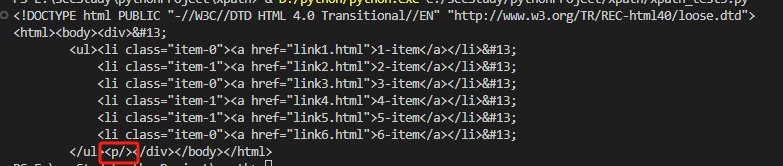
result = html.xpath('//*')
print(result)
结果:
[<Element html at 0x2a97b4dbb00>, <Element body at 0x2a97b4dba80>, <Element div at 0x2a97b4dbb40>, <Element ul at 0x2a97b4dbb80>, <Element li at 0x2a97b4dbbc0>, <Element a at 0x2a97b4dbc40>, <Element li at 0x2a97b4dbc80>, <Element a at 0x2a97b4dbcc0>, <Element li at 0x2a97b4dbd00>, <Element a at 0x2a97b4dbc00>, <Element li at 0x2a97b4dbd40>, <Element a at 0x2a97b4dbd80>, <Element li at 0x2a97b4dbdc0>, <Element a at 0x2a97b4dbe00>, <Element li at 0x2a97b4dbe40>, <Element a at 0x2a97b4dbe80>]
result = html.xpath('//li')
print(result)
结果:
[<Element li at 0x2230f19ba40>, <Element li at 0x2230f19bb00>, <Element li at 0x2230f19bb40>, <Element li at 0x2230f19bb80>, <Element li at 0x2230f19bbc0>, <Element li at 0x2230f19bc40>]
result = html.xpath("//li/a")
print(result)
结果:
[<Element a at 0x2bfad419b40>, <Element a at 0x2bfad419c00>, <Element a at 0x2bfad419c40>, <Element a at 0x2bfad419c80>, <Element a at 0x2bfad419cc0>, <Element a at 0x2bfad419d40>]
result = html.xpath("//li[@class='item-0']")
print(result)
结果:
[<Element li at 0x296ed746c80>, <Element li at 0x296ed746cc0>, <Element li at 0x296ed746d00>]
result = html.xpath('//a[@href="link6.html"]/../@class')
print(result)
result = html.xpath('//a[@href="link6.html"]/parent::*/@class')
print(result)
结果:
['item-0']
result = html.xpath("//li[@class='item-1']/a/text()")
print(result)
结果:
['2-item', '4-item', '5-item']
result = html.xpath("//li/a/@href")
print(result)
结果:
['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html', 'link6.html']
text = '''
<li class="li item-0"><a href="link1.html">1-item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class,li)]/a/text()')
print(result)
结果:
['1-item']
text = '''
<li class="li item-0" name="r1cky"><a href="link1.html">1-item</a></li>
<li class="li item-0"><a href="link1.html">2-item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class,li) and @name="r1cky"]/a/text()')
print(result)
结果:
['1-item']
xpath节点的运算符
= :判断两个值是否相等
!=
<
>
>=
<=
逻辑运算符
and
or
not
字符串运算符:
concat():将多个字符串连接
starts-with():检查字符串是否以指定的前缀开头
contains():检查是否包含某个字符串
substring():从字符串截取子字符串
数字运算符:
+
-
*
/
%
按顺序选择
在标签中使用[]标识位置
last()最后一个
position()查询指定为位置的前几位
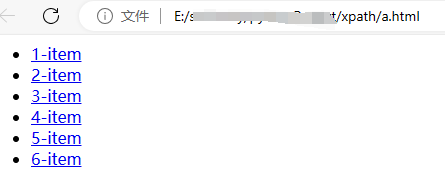
result = html.xpath('//li[1]/a/text()')
print(result)
result = html.xpath('//li[last()]/a/text()')
print(result)
result = html.xpath('//li[position()<3]/a/text()')
print(result)
result = html.xpath('//li[last()-2]/a/text()')
print(result)
结果:
['1-item']
['6-item']
['1-item', '2-item']
['4-item']
|